
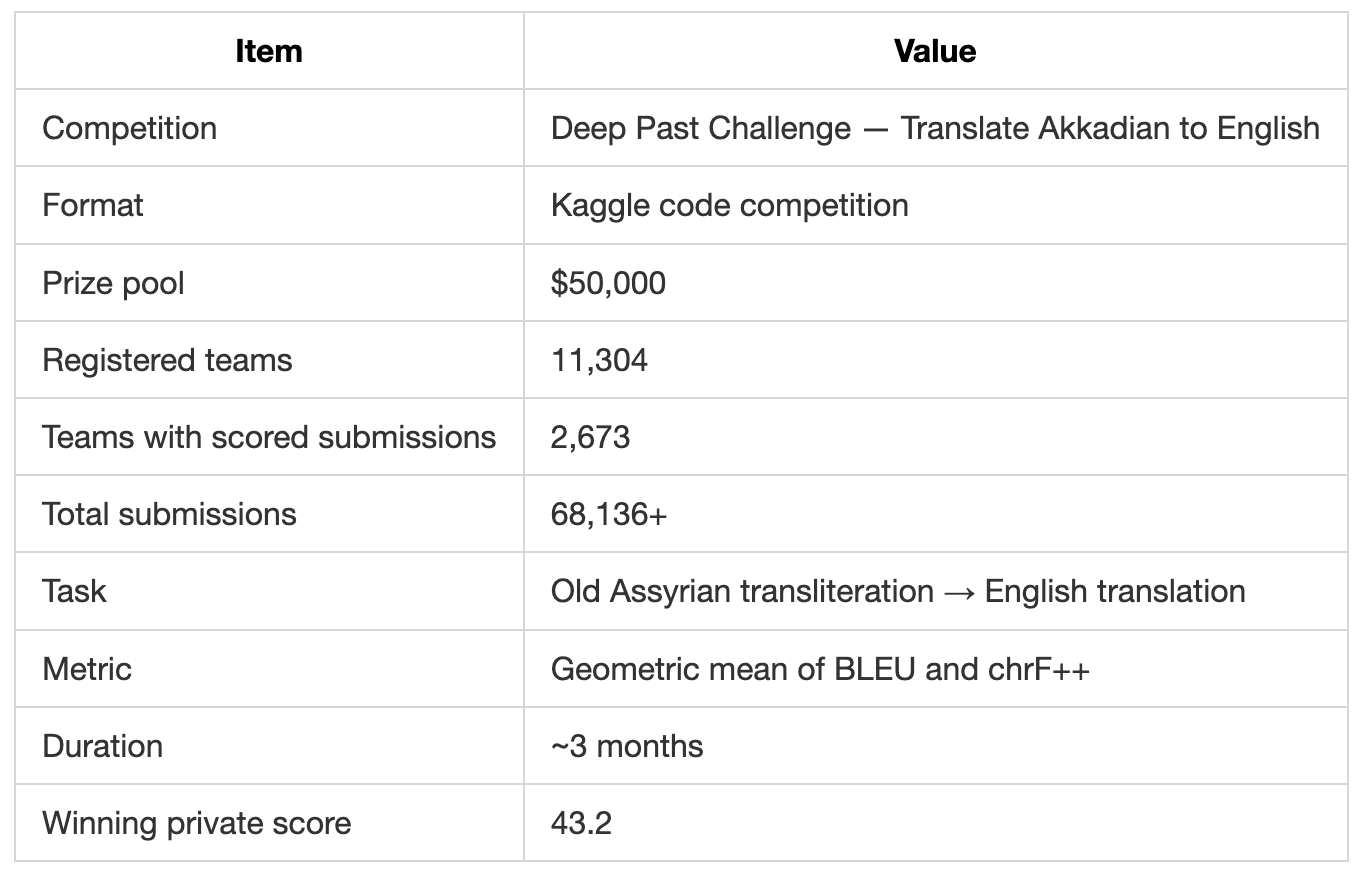
Deep Past Challenge: Lessons from Kaggle’s Akkadian-to-English Translation Competition
How top teams translated 4000 years-old Assyrian tablets into modern English, and what the competition revealed about data engineering under low-resource, noisy conditions.

TL;DR
The Kaggle Deep Past Challenge combined tiny official supervision, noisy OCR, unstable orthography, hidden distribution shift, and a metric sensitive to both adequacy and surface form.
The highest-ranked teams separated themselves not through clever modeling, but through rigorous data preparation: corpus construction, alignment, normalization, and validation discipline.
Across the top write-ups, the same lesson appears repeatedly:
Data quality beats clever modeling tricks.
That makes the competition technically very close to real life projects and extremely interesting to study.
Competition Overview
The task
Participants had to translate Old Assyrian transliterations into English.
The task description sounds straightforward until one inspects the source representation. The input departs substantially from modern orthography. It included:
diacritics such as
š,ḫ,ṣ, andṭ,subscript numerals,
determinatives in braces such as
{d}and{ki},Sumerograms,
and damage markers such as
<gap>, which indicate missing or unreadable text in the source.
The target side was also constrained. It required scholarly English translations where names, numbers, uncertainty, and damaged passages had to be rendered consistently.
The dataset
The competition data was not a single clean parallel corpus. It was a bundle of resources with very different roles: one small supervised training table, several metadata and lexical tables, and one very large OCR dump of academic PDFs.
train.csv
1,561 rows, 3 columns: oare_id, transliteration, translation.
The official supervised dataset, but at document level.
Samples could be a short sentence like this
1 TÚG ša qá-tim i-tur₄-DINGIR il₅-qé
-> Itūr-ilī has received one textile of ordinary quality.or a text with thousands of characters.
Some stats:
42.9% of training transliterations contained
<gap>markers,source lengths ranged from 21 to 966 characters, with a median of 371,
and target lengths ranged from 6 to 3,995 characters, with a median of 383.
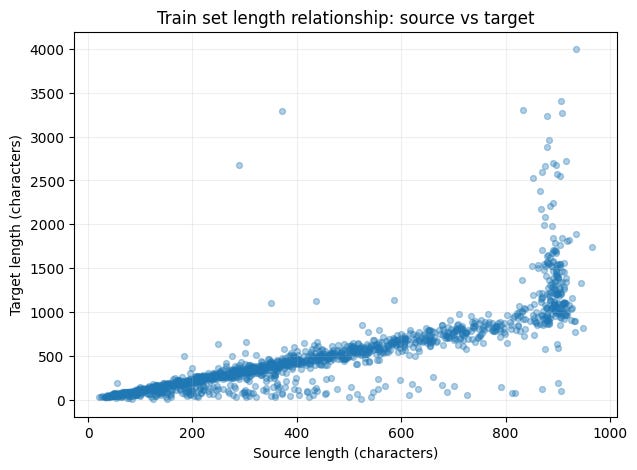
Most importantly: Train and test are different distribution. Train data are document level, while test samples are sentences-pair.
Other released files
The rest of the bundle mattered for different reasons. None of these files is a ready-made translation table, but each one helped competitors reconstruct, normalize, or expand the corpus.
published_texts.csv
7,953 rows, 19 columns.
This is the catalogue layer: one row per text, keyed by oare_id, with identifiers, publication metadata, and links back to transcript resources. A typical row is mostly metadata rather than language content, so this file was useful for joins and provenance, not for direct model training.
Sentences_Oare_FirstWord_LinNum.csv
9,782 rows, 12 columns, spanning about 1,700 texts.
This is the most useful bridge file because it breaks texts into sentence-like units and preserves line information. A sample row combines an oare_id, a transliterated sentence, its English translation, the first word, and line metadata. That structure is much closer to the hidden test setup than the document-level rows in train.csv, which is why many teams used it to rebuild sentence-level supervision.
OA_Lexicon_eBL.csv
39,332 rows, 9 columns.
This is a lexicon, not parallel data: surface forms, normalized spellings, lexemes, and glossary fields. For example, forms such as áb ša-ra-ni appear next to normalized variants like ab šarrānē. That kind of mapping is valuable for normalization, OCR repair, and lexical grounding, but it does not by itself provide full translation pairs.
eBL_Dictionary.csv
19,215 rows, 3 columns.
This is the simplest reference table: a word, a definition, and a derivational hint. An entry such as -a I → "my" (1 sg. pron. suff.) shows the level of granularity. Useful for terminology and morphology checks, but still not supervision on its own.
publications.csv
216,602 rows, 4 columns, extracted from 952 PDFs.
This was the biggest prize in the release and also the noisiest one: page-level OCR text from academic publications, plus metadata and a has_akkadian flag. Only 31,286 pages, about 14.4% of the archive, were flagged as containing Akkadian, so even basic filtering mattered.
The raw text can look like Kleine Mitteilungen\nAltassyrische Miszellen 2..., which immediately shows that this file contains potential evidence, not aligned supervision.
Top teams mined this archive aggressively because it was the only realistic path from 1.5K gold pairs to a much larger in-domain corpus.
In short, the dataset was less a ready-made MT benchmark than a small gold core sitting inside a much larger, noisier research archive.
The metrics
The competition metric was the geometric mean of BLEU and chrF++. That combination mattered because a prediction had to preserve both phrase-level meaning and scholarly surface detail: names, morphology, spelling conventions, and small character distinctions.
Suppose the reference is:
Itūr-ilī has received one textile of ordinary quality.
Now compare two deliberately imperfect predictions, using real single-example scores:
Example 1:
Ordinary quality textile one received by Itūr-ilī.Example 2:
He has received one ordinary textile
BLEU is based on matching word n-grams: first single words, then 2-word, 3-word, and 4-word sequences, plus a brevity penalty for outputs that are too short. In plain English, BLEU asks whether the system preserved the same local wording and phrase order as the reference.
chrF++ works differently. It computes an F-score from overlapping character n-grams and then augments that with word n-grams — that is the ++ part. So chrF++ is more sensitive to shared stems, endings, names, spelling conventions, and near-matching surface form, even when the full phrase structure is weaker.
Here are the actual scores:
Example 1: BLEU = 7.63, chrF++ = 57.62
Example 2: BLEU = 20.82, chrF++ = 49.84
This already shows the difference between the two metrics. Example 1 preserves most of the original content words and even keeps the name Itūr-ilī, so its character overlap remains fairly high. But the phrase order is badly scrambled, which crushes its BLEU. Example 2 loses the proper name and drops quality, so its surface overlap is weaker, but it keeps a much more natural local phrase structure, which lifts BLEU substantially.
The useful part comes when the two metrics are blended. If we used a simple arithmetic mean, the scores would be:
Example 1:
(7.63 + 57.62) / 2 = 32.62Example 2:
(20.82 + 49.84) / 2 = 35.33
But the competition did not use an arithmetic mean. It used the geometric mean:
Example 1:
sqrt(7.63 × 57.62) = 20.96Example 2:
sqrt(20.82 × 49.84) = 32.21
So Example 2 gets the better final score. That is the key intuition behind the metric: the geometric mean rewards balance and punishes systems that are strong on only one axis. A very low BLEU or a very low chrF++ drags the final score down sharply.
In Deep Past, that was a sensible design. It discouraged systems that merely preserved names, stems, and character fragments while mangling local phrasing, and it also discouraged more fluent rewrites that smoothed away philologically important surface detail. To score well, a model needed both reasonably good phrase-level structure and reasonably good character-level fidelity.
The key challenges
The competition was difficult for four reasons.
1. Very little clean supervision
The official training set contained only 1,561 labeled pairs, which is tiny for machine translation. More importantly, the released supervision was mostly document-level, while the hidden evaluation was sentence-level. Teams therefore had to create better supervision before they could train better models.
2. An unusual source representation
Old Assyrian transliterations are packed with character-level information: rare Unicode, subscripts, determinatives, Sumerograms, and damage markers such as <gap>. These are not cosmetic details. They carry meaning, and they make standard tokenization much less reliable than in modern-language MT.
3. Valuable but noisy expansion data
The largest resource, publications.csv, contained 216,602 OCR-extracted pages. That archive was potentially far more valuable than the official train set, but it was noisy, weakly structured, and often multilingual. Converting it into usable sentence pairs required extraction, alignment, filtering, and repeated cleaning.
4. Unstable validation
The public leaderboard was a weak proxy for the final task. Based on the competition review and leaderboard reconstruction, 48.3% of teams improved on the private leaderboard and 49.6% dropped, with rank shifts ranging from +700 to -1,412 places. That made leaderboard chasing risky and increased the value of conservative validation and robust decoding.
2. Winners’ solutions
What is most striking about the winning teams is the extent to which they converged on the same view of the problem, even when their pipelines differed.
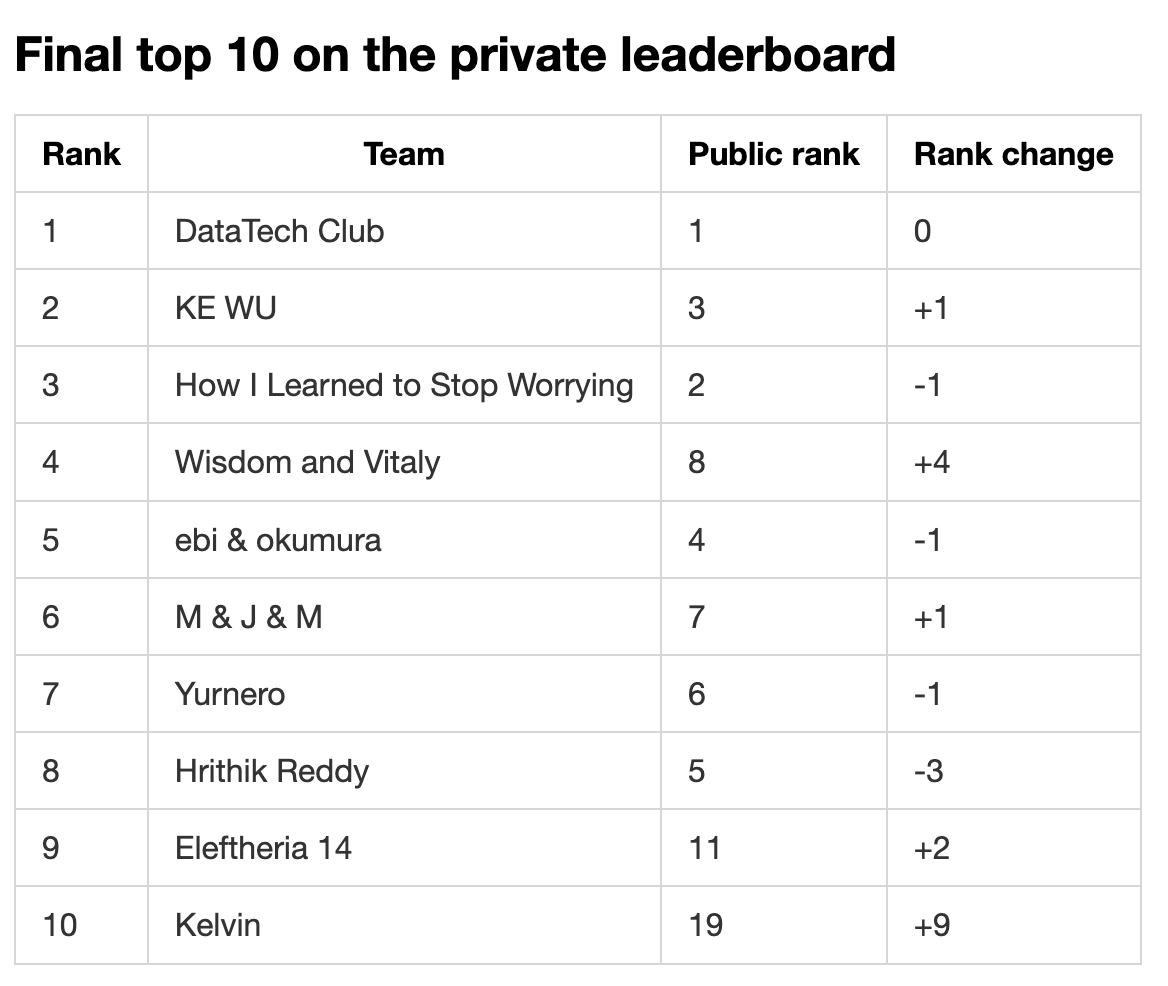
The details differ, but the pattern is consistent: the strongest teams treated the bottleneck as data quality and data construction, not architecture invention.
2.1 The shared pattern across top teams
Before looking at individuals, here is the high-level convergence.
Let’s dive into the novelty of each solution.
2.2 First place: DataTech Club
Private score: 43.2
The winning solution summary is the clearest expression of the competition’s main lesson: once the backbone is strong enough, the real game is building better supervision.
Full solution
Data preparation. DataTech Club took the boldest possible stance on data quality: they effectively replaced the official supervision with their own reconstructed corpus. Instead of treating train.csv as the foundation, they extracted sentence pairs directly from PDFs and iterated on that extraction several times. Their successive datasets grew from about 29.9K to 34.1K pairs as they re-extracted bad cases, filtered mismatched examples, and improved error detection. On top of that, they added LLM-labeled examples from the OARE database and synthetic examples designed to fill lexical gaps.
What stands out is not just the size of the reconstructed corpus, but the care with which it was built. They distinguished between well-structured books and badly structured ones, used different extraction strategies for each, and emphasized that alignment had to follow logical meaning, not physical tablet lines. They also relied on philological anchors such as numbers, Sumerograms, and proper names, plus an understanding of tablet layout, to align transliterations and translations correctly.
Modeling. Their final system was an ensemble of 11 ByT5-XL models. The model choice itself was not exotic: it matched the now-standard conclusion that byte-level modeling handled the character irregularities of Old Assyrian best. The interesting part is how tightly model quality depended on dataset quality. Their own write-up shows that even a single strong ByT5-XL trained on the right data was already extremely competitive.
Evaluation and model selection. They were unusually disciplined here. Instead of chasing validation BLEU or public leaderboard spikes, they trusted eval_loss as the main checkpoint selection signal. Their reasoning was that local BLEU and chrF++ became unreliable late in training because the hidden test distribution differed from local validation. They also used cross-validation not only to estimate model quality, but to detect bad extracted samples and send them back into the data-cleaning loop.
Ensembling and post-processing. Inference was equally pragmatic. Each model produced multiple candidates via beam search and temperature-based sampling, then the final prediction was chosen with MBR decoding using a blend of chrF++, BLEU, Jaccard overlap, and length-sensitive heuristics. They also optimized inference operationally with quantized ct2 models. Just as important, they resisted the temptation to over-polish outputs after decoding. Their best private submission was the one with minimal post-processing.
Why they finished first
they treated corpus construction as the main modeling problem, not a preprocessing side quest
they improved extraction quality iteratively instead of assuming one pass was enough
they paired a strong but standard backbone with unusually strong validation discipline
they used MBR to stabilize inference without relying on brittle hand-tuned output fixes
they avoided public-leaderboard bait and optimized for generalization under distribution shift
Winning team ensemble overview
2.3 Second place: KE WU
Private score: 41.0
The second-place solution summary is the cleanest counterpoint to first place. It reached nearly the same conclusion about the task, but with a simpler modeling stack and a more classical data-engineering pipeline.
Full solution
Data preparation. KE WU framed the competition directly as a data bottleneck problem. Their pipeline began with a three-stage LLM segmentation process that converted the released resources into sentence-level pairs: a breaker stage for segmenting translations using OARE anchors, a fixer stage for repairing corrupted fragments, and a generator stage that was later abandoned because it added noise instead of value. They then mined about 60K sentence pairs from 149 academic sources, spanning English, Turkish, French, and German scholarship. Non-English sources were translated to English during extraction, and repeated extraction of non-English material created useful target variation.
Their normalization rules were also more explicit than most: they standardized diacritics, subscripts, hamza variants, and determinatives so that equivalent forms from different publications mapped to a more consistent byte sequence. One small but telling decision was prefer-EN deduplication: when the same tablet appeared in English and another language, they kept the English version instead of creating conflicting targets.
Modeling. Unlike first place, KE WU stayed with a vanilla ByT5-large. No architectural changes, no reward model, no complex ensemble. They also augmented training with 768-byte document chunks so the model sometimes saw neighboring sentence context.
Evaluation. Their training setup was standard but carefully tuned: Adafactor, long training, length grouping, and checkpoint selection based on the run that aligned best between public and private behavior rather than the one with the highest public score. The write-up is a useful reminder that a pipeline can be technically simple and still very strong if the data are clean enough.
Inference and post-processing. They kept inference conservative: no post-processing in the final submission. They tested dictionary-based name corrections, but these did not improve results consistently, likely because the hidden test set mixed conventions from many publications.
What differs from first place
Compared with DataTech Club, this solution is less aggressive on ensembling and less dependent on bespoke extraction iterations. The main lesson is that you could get almost all the way to the top with cleaner sentence construction, multilingual source mining, normalization, and one good byte-level model. That makes KE WU the strongest evidence that the competition rewarded data design more than modeling complexity.
2.4 Third place: How I Learned to Stop Worrying
Private score: 40.9
The third-place solution summary is where the competition becomes more interesting from a modeling perspective. It still depends heavily on data work, but it adds the clearest synthetic-data curriculum among the top teams.
Full solution
Data preparation. This team combined several real-data streams—competition resources, sentence-level reconstruction, PDF extraction, OCR-derived publications, and pseudo-labels—with a very large synthetic program. Their synthetic data were not generic paraphrases. They deliberately generated vocabulary drills, grammar drills, slot-filled transactional templates, contrastive personal-name examples, weight-conversion examples, and even coherent tablet-like multi-sentence cases. In other words, they used synthetic data to teach Old Assyrian structure before expecting the model to imitate scholarly translations.
Modeling. Their pipeline had two stages. First came continued pre-training, meant to teach the model vocabulary, morphology, and formulaic patterns. Then came fine-tuning, focused on high-quality scholar-translated pairs and translation style. The final system ensembled ByT5-Large and ByT5-XL outputs, then used a fine-tuned Qwen3-8B reward model to choose the better sentence-level candidate.
Evaluation. The strongest evidence in the write-up comes from ablations. Direct fine-tuning on scholar data was already decent, but CPT helped slightly, and structured synthetic drills helped more. Adding pseudo-labeled data pushed performance a little further. Their checkpoint analysis also showed a useful training dynamic: rapid early learning, a middle phase of refinement, and then regression if training continued too long.
Ensembling and post-processing. Instead of classic MBR across many models, they used pairwise reranking between two strong model outputs. That made the final system more selective and arguably more interpretable: the reward model acted as a judge rather than averaging a large ensemble.
What differs from the top two
This was the first top solution that clearly tried to teach the model the language, not just expose it to more extracted supervision. Compared with first and second place, it spent more effort on curriculum design, synthetic drills, and reward-model reranking. That makes it the most instructive solution for anyone interested in low-resource MT when the raw corpus is not enough and synthetic data must carry real linguistic structure.
Third-place ensemble and reranking setup
2.5 Fourth place: Wisdom and Vitaly
Private score: 40.9
The fourth-place solution summary sits much closer to first place than its rank jump might suggest. It is another strong example of rebuilding the corpus from PDFs and then using robust decoding to suppress hallucinations.
Full solution
Data preparation. Like the winner, Wisdom and Vitaly discarded the official train.csv and rebuilt their dataset from PDFs, ending with about 14.5K curated samples plus selected external material such as Barjamovic. They first tried a more conventional OCR path with PyMuPDF and Tesseract, but found it too brittle for apostrophes, quotes, and superscripts. They then switched to Gemini-based extraction from page images, using prompts that explicitly preserved superscripts and subscripts. For non-English books, they used fast machine translation to convert the English side. Alignment combined automated splitting heuristics with manual inspection and targeted Gemini assistance for uncertain cases.
Modeling. Their model family was more diverse than the teams above: mT5-Large, ByT5-Large, ByT5-XL, and a ByT5-Large variant with higher dropout. They also found that checkpoint averaging improved validation performance.
Evaluation. Their validation set came from AKT 6d, a book they held out after processing it last. They selected models by chrF++ on that set. They also tuned a relatively aggressive length penalty, which improved validation consistently.
Ensembling and post-processing. The final submission used ensemble MBR decoding over 10 candidates produced by four different models. Candidate selection was based on average chrF++ agreement with the rest, which helped reject outlier or hallucinatory translations. Post-processing was deliberately tiny: essentially only fraction formatting. As with the higher-ranked teams, restraint at inference mattered.
What differs from the teams above
Compared with first place, the reconstructed corpus was smaller and the validation setup narrower, but the overall philosophy was similar: replace the weak official supervision, normalize hard, and trust robust decoding over elaborate output edits. Compared with KE WU, this solution leaned more heavily on model diversity and consensus decoding rather than on one large, carefully normalized corpus.
2.6 Fifth place: ebi & okumura
Private score: 40.8
The fifth-place solution summary is the strongest example in the top five of a classic MT idea being adapted successfully to this domain: back-translation.
Full solution
Data preparation. The team built about 20K PDF-extracted pairs with a multi-step VLM pipeline: detect tablet headings, link them to structured competition resources, extract transliteration/translation pairs under different layout assumptions, and translate non-English sources to English. They also incorporated EvaCun, a separate transliteration-translation resource of about 45K pairs, after a small normalization step that removed repeated word noise.
Modeling. Their best backbone was ByT5-XL. Training was staged: first continued pre-training on transliterations from published_texts.csv, then fine-tuning on EvaCun, then fine-tuning on PDF-extracted competition-domain data. Crucially, they trained both a forward model and a reverse English→Akkadian model.
Evaluation. They used a 25% hold-out split from train.csv, stratified by source/target length ratio, and found that token-level validation loss correlated well with leaderboard movement. That gave them a more stable basis for ablations than public-score chasing.
Synthetic data, inference, and context. Their distinctive contribution was synthetic data via back-translation. The forward model pseudo-labeled unlabeled transliterations, while the reverse model turned generated English sentences back into Akkadian to produce extra training pairs. They also added limited tablet context by prepending previous lines. Unlike most other top-five teams, their final submission was not a large ensemble: it relied on a strong single model with weight averaging and beam search. That makes the pipeline simpler operationally, even if the data generation logic was sophisticated.
What differs from the teams above
Compared with third place, this solution used synthetic data in a more classical MT sense: not a curriculum of linguistic drills, but a back-translation loop to create new parallel text. Compared with first and fourth place, it relied less on MBR-heavy ensembles and more on staged training plus synthetic expansion. It is probably the most transferable top-five recipe if one wants a strong pipeline without maintaining many inference-time models.
2.7 Other notable solutions
The top five explain most of the leaderboard, but the remaining high-ranked write-ups are still useful because they each isolate one extra lesson.
M & J & M (#6)
The 6th-place write-up pushed PDF processing sophistication further than almost anyone else. They classified PDFs into multiple structural types, used separate extraction logic for each, translated Turkish sources, added heavy regex and LLM cleaning, and trained a 15-model ensemble with robustness tricks such as R-Drop and PGD. Compared with the top five, this is a more systems-heavy, engineering-maximalist version of the same data-first philosophy.
Yurnero (#7)
Yurnero did not introduce the most novel modeling idea, but the solution is useful as another confirmation that the competition could be attacked successfully without radical architecture changes. It reinforces the broad pattern: strong byte-level sequence models, more usable external pairs, and disciplined training mattered more than clever novelty.
Hrithik Reddy (#8)
The 8th-place solution summary is one of the clearest demonstrations of broad noisy pre-fine-tuning followed by cleaner specialization. A first stage on roughly 350K noisy pairs, then a second on about 65K curated pairs, produced a very readable version of the staged-data recipe seen elsewhere. Compared with the top five, it is simpler and more direct, which makes it a good practical template.
Eleftheria 14 (#9)
The 9th-place write-up may be the most rigorous public write-up on data engineering itself. With roughly 163K extracted pairs, OCR comparisons, 30-plus cleaning passes, repair-over-removal logic, and source-grounded MBR, it shows how much performance can come from meticulous pipeline quality. Relative to the top five, it is especially valuable as a technical reference for OCR, normalization, and repair strategy.
Kelvin (#10)
The 10th-place solution summary is a clean CPT → SFT → pseudo-label pipeline across ByT5 and MADLAD variants. It is less distinctive than the top five, but useful because it demonstrates that a relatively standard modern multilingual-MT recipe still worked in this domain once adapted to the data.
DataBoom (#13)
The 13th-place solution summary deserves mention because it focused on source repair at test time. That is different from most top-five approaches, which concentrated more on training data quality or candidate selection. In noisy historical text, fixing the corrupted input can sometimes be a better investment than polishing the output after decoding.
Key Learnings
This is the section worth carrying into other projects.
Learning 1: Data quality beat model novelty
The strongest consensus across the winning solutions is simple:
The decisive gains came from extraction, cleaning, alignment, and normalization—not from novel architecture design.
That does not mean models were irrelevant. But once the field converged on strong sequence-to-sequence backbones, the margin came from the quality of the training signal.
This is relevant well beyond ancient-language translation. In many real systems, teams overinvest in model changes and underinvest in supervision quality.
Deep Past punished that imbalance very clearly.
Learning 2: ByT5 was the right inductive bias
Byte-level modeling dominated for a reason.
ByT5 was especially well matched to this task because:
character distinctions mattered,
token boundaries were unstable,
rare symbols were meaningful,
and orthographic variation was too messy for standard subword approaches.
Several teams tested alternatives and still converged on the same conclusion: in this competition, byte-level sequence modeling was the safest and strongest default.
Learning 3: LLMs were most useful upstream
A striking pattern across the top solutions is that LLMs created the most value before the final translation model was trained.
They were used for:
OCR assistance,
segmentation,
alignment,
translation of non-English scholarship,
data filtering and judging,
synthetic data generation,
and iterative error analysis.
By contrast, last-mile LLM post-processing often failed to help and sometimes hurt.
That is a very transferable lesson: in messy ML pipelines, LLMs often create more value as data workers than as final answer polishers.
Learning 4: Synthetic data worked when it taught structure
Not all synthetic data helped equally.
The best synthetic pipelines contributed more than extra text volume. They taught:
vocabulary,
morphology,
grammar,
common semantic slots,
and domain-specific patterns.
That is why the third-place solution is so instructive. Its synthetic data worked because it behaved like a curriculum.
The broader lesson is:
Synthetic data is most useful when it encodes domain structure, not when it merely inflates dataset size.
Learning 5: Robust decoding generalized better
MBR decoding appears again and again across top teams because it fits the task well.
When the output space is noisy and the metric rewards both adequacy and surface fidelity, the most probable beam is not always the safest answer. MBR tends to select outputs that are more stable relative to a pool of plausible candidates.
In Deep Past, that often translated into better private leaderboard performance.
Learning 6: Repair often beats removal
One of the most valuable ideas in the top write-ups was the philosophy of repair over removal.
In a web-scale setting, filtering aggressively is cheap. In a low-resource historical setting, it can be very expensive. If you can repair a noisy example with high enough precision, preserving it may be much better than discarding it.
This principle appeared in:
OCR repair,
diacritic recovery,
gap normalization,
sentence realignment,
determinative cleanup,
and source repair before inference.
That is a powerful lesson for any low-resource pipeline.
Learning 7: Public leaderboard optimization was a trap
The large public/private shake-up should be treated as a warning sign.
The strongest teams responded accordingly:
they distrusted superficial gains,
they preferred stable validation signals,
they selected checkpoints conservatively,
and they optimized for robustness.
That mindset often separates a good Kaggle score from a solution with a better chance of surviving real deployment.
5. Final Takeaway
The simplest description of the Deep Past Challenge is that it was a competition about translating Akkadian into English.
The more accurate description is that it was a competition about making translation learnable under low data regime.
The best teams built more than models. They built:
corpora out of messy scholarship,
aligned pairs out of document-level noise,
signal out of OCR damage,
and robust predictions out of uncertain candidate sets.
This competition is very valuable because it is very close to a real project scenario where data is scarce and noisy.
That’s also the kind of project we want to empower at Jovyan AI - with our AI agents purposely built for data science. Btw, the AI agent explored of data and winners solution and wrote most of this article.
Further Reading
For deeper detail, the most useful public sources are: